Architecture and data flow
Overview
The Reporting and Data Analytics Platform integrates with Oracle applications like ORMB Healthcare, supporting real-time and batch data processing for quick insights. The Data Capture Layer allows data ingestion with tools like Oracle GoldenGate for low-latency and GDE and DTEX for batch processing. Semi-structured data is stored in Object Storage for consistency.
The Data Storage and Processing Layer manages the data lifecycle using workflow schedulers across different layers, with data stored in systems like OCI Object Storage and AWS S3 for scalability. The Semantic and Query Layer enables users to create reports using common terms, while the Meta Store ensures governance and version control.
The Information Layer offers access through dashboards and self-service options without requiring SQL skills. Key benefits include scalability, flexible ingestion, and fast querying, turning raw data into business insights.
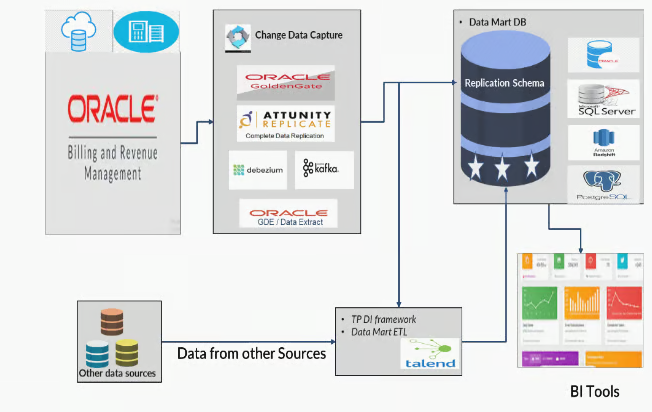
Data Sources and Ingestion Workflow
RDA has a data acquisition layer that connects with both SaaS and on-premise ORMB Healthcare deployments and various enterprise systems. It supports low-latency and scheduled reporting.
For near real-time ingestion, CDC (Change Data Capture) tools acquire data directly from source systems, enabling continuous synchronization of transactional changes.
For batch extraction, the platform uses native tools like GDE (Generalized Data Extract), DTEX, and ORDS, which are designed for scheduled jobs and dynamic queries focused on healthcare billing and claims data.
In Oracle Cloud Infrastructure (OCI), GDE and SDE services extract transactional changes from ORMB environments. The ORMB application includes scheduling capabilities for reliable job execution. Extracted data is stored in OCI Object Storage for scalable and secure staging for validation, transformation, and analytics.
Reporting and Data Analytics
RDA features a modular analytics engine made up of three integrated layers: the data pipeline, the SQL engine, and the reporting interface.
Data Pipeline
The data transformation engine ingests raw data, applies cleansing and business logic, and validates quality at each stage. Its modular design includes audit hooks for traceability and SLA compliance. In both ETL and ELT modes, the pipeline supports automated retries, lineage tracking, and metadata propagation for resilience and transparency.
Once data is in Cloud Object Storage, the Data Pipeline tool models and transforms it into structured datasets, saving them as Data Lakehouse objects for fast queries, schema evolution, and semantic abstraction.
SQL Engine and Semantic Modeling
The Data Lakehouse’s SQL engine allows users to access data with familiar SQL syntax, while its semantic layer transforms complex data relationships into user-friendly views. It supports Iceberg tables for Time-Travel capabilities, enabling historical queries for audit and trend analysis. Metadata services and warehouse catalogs provide schema discoverability, version control, and governance throughout the data lifecycle.
Reporting Engine
Business value is delivered through the Reporting Interface, which supports interactive dashboards, authored reports, and ad hoc exploration. The built-in reporting tool allows stakeholders to visualize insights, monitor KPIs, and analyze metrics, all within a secure role-based access control (RBAC) framework. The semantic layer maintains consistent metric definitions, reducing ambiguity and improving decision-making across teams.
Data Storage and Format Strategy
RDA supports flexible storage backends to meet enterprise needs. Object stores like OCI OS, ADLS, S3, and MinIO offer scalable cloud-native options, while HDFS caters to legacy deployments. Data Lakehouse objects are stored in Parquet and Iceberg table formats within Cloud Object Storage, ensuring high-performance access and compatibility with advanced analytics frameworks. Storage tiering and lifecycle policies can be implemented to optimize cost, performance, and compliance for archival purposes.
Data Governance
A data governance framework supports the architecture, ensuring data is managed with integrity and transparency. It includes role-based access control (RBAC), lineage tracking, and metadata management for schema evolution and cataloging. Audit controls are embedded throughout the system to track data movement and transformation and assure data quality. These controls validate consistency, completeness, and accuracy in reporting layers, fostering trust in the insights provided to stakeholders.